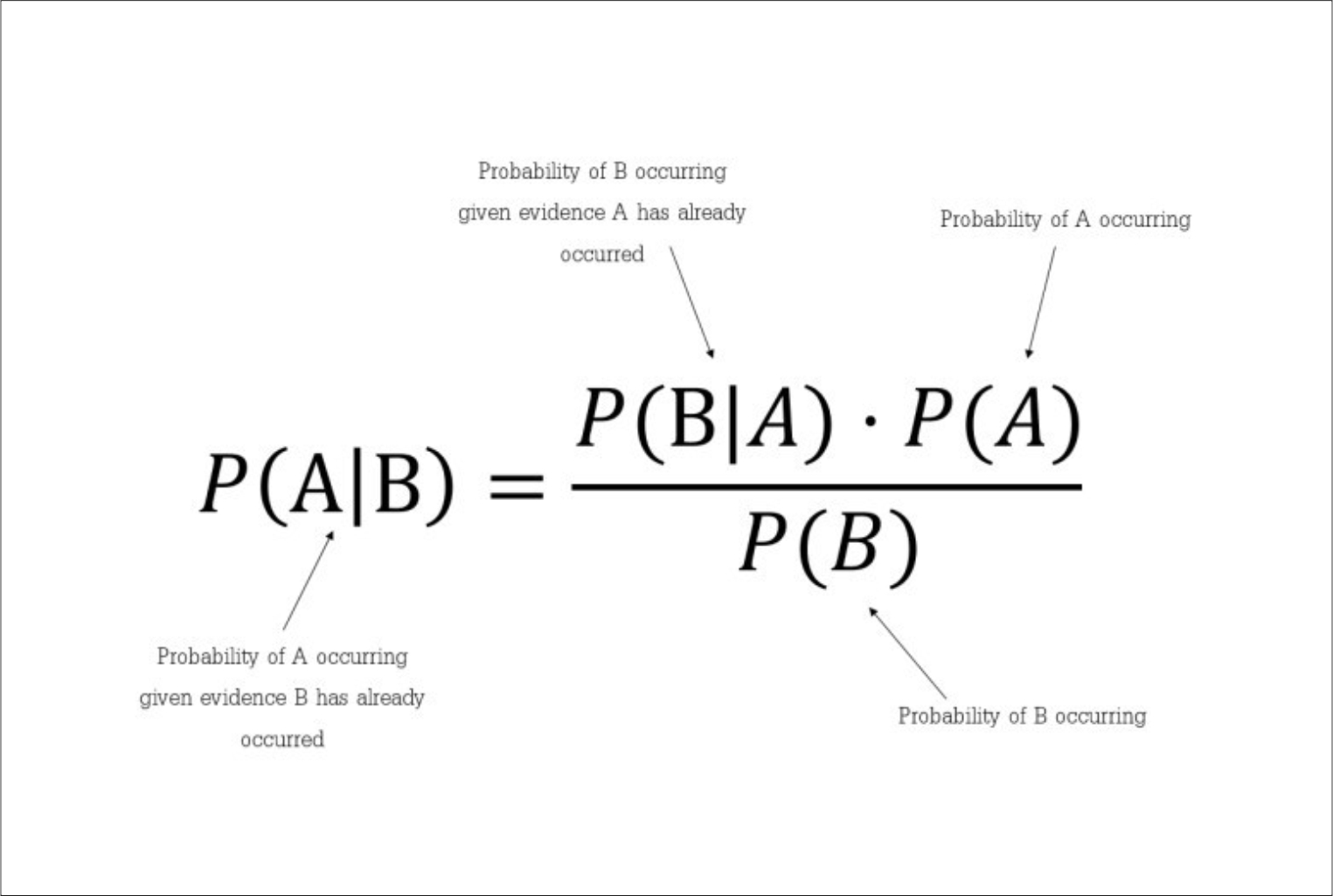
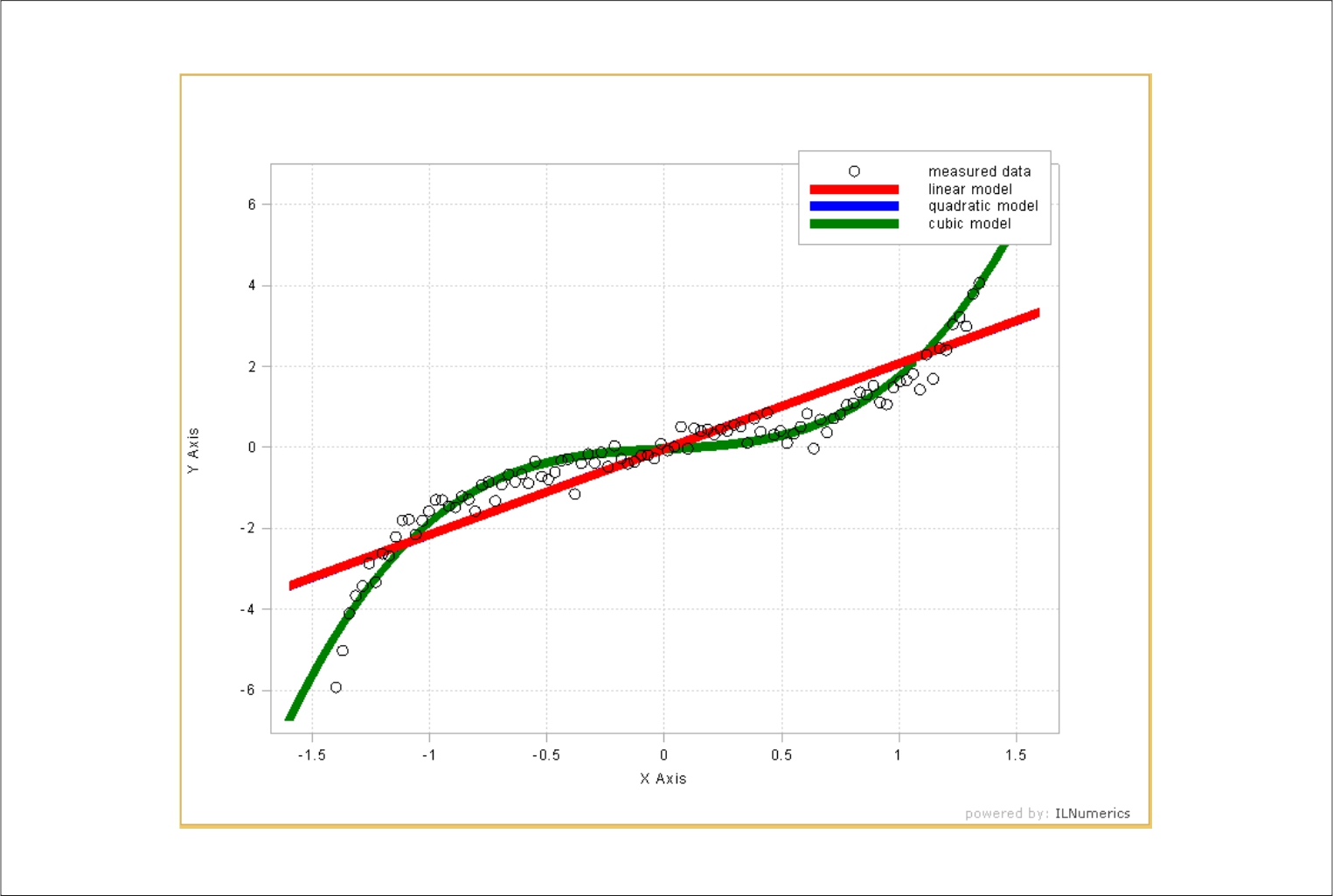
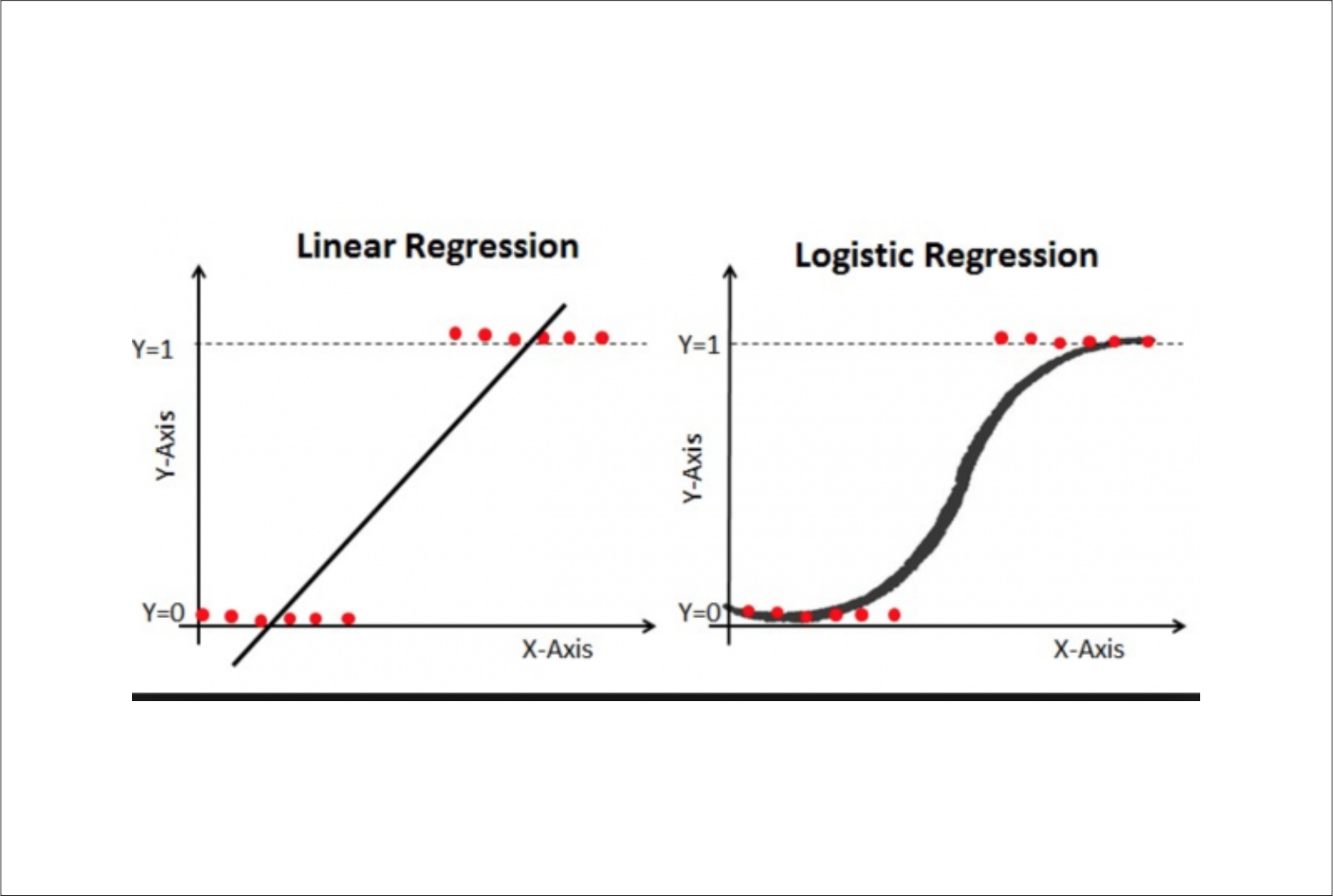
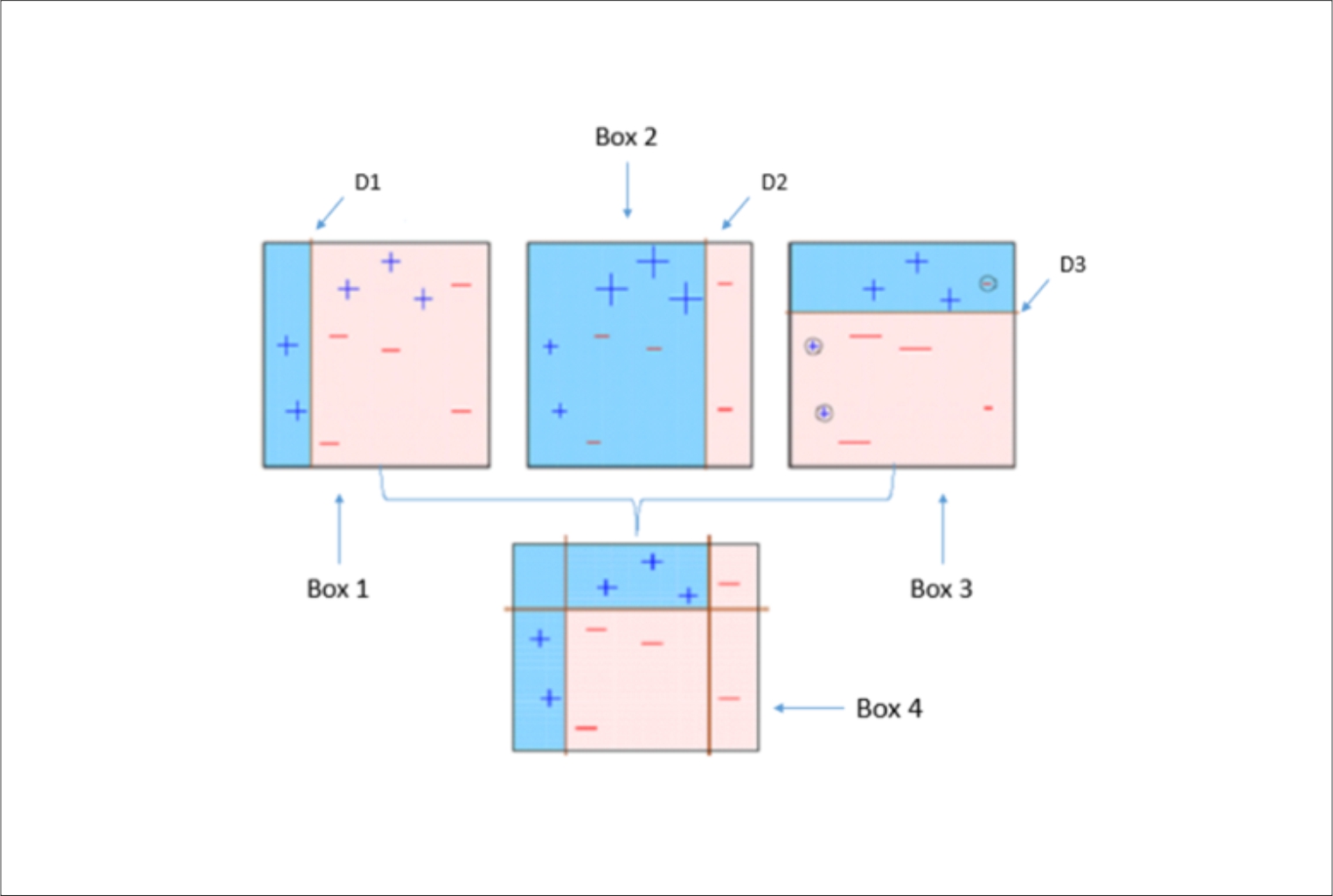
About Me
Hi! My name is Ivan Muhammad Siegfried. I took my Master Degree in Physics and graduated from Institut Teknologi Bandung in 2019 and took my Bachelor in Physics from Padjadjaran University in 2016. I have strong interest in Computational Physics especially on Density Functional Theory, Computational Fluid Dynamics, Heat Transfer, and Instrumentation as well. Now, I focus on Data Science, Machine Learning, Computer Vision. I am currently working in private sector focusing on developing applied technologies that can improve human life.
Codes
These are programming languages and tools that I mastered.I often use Python as main programming language for Data Science, Machine Learning, Computer Vision etc. The other languages are used for me to solving Computational Physics problem.
Other Softwares, Tools, and Platforms